





In the earlier parts of this series we explored ways of evaluating scientific writing by considering the critical issues of study design, assignment of study and control groups, assessment of outcome, and finally, interpretation and extrapolation of results.
When a new test is developed, and this could be a laboratory test, an orthopaedic test, an electrodiagnostic test, etc., it is tested against the existing gold standard test. Two of the most commonly reported results are sensitivity and specificity. Sensitivity is a measurement of the proportion of people who actually have the disease and are correctly identified, i.e., the percentage of true positives. Conversely, the specificity of a test is a reflection of the proportion of those who do not have the disease and who are correctly identified as being disease-free by the test. These measures tell us only the proportions of people who are diseased and disease-free. Most importantly, these figures measure the discriminate ability of the test. Let's look at an example of a new test which is compared to the existing gold standard. In this study we have 1,000 individuals, of which 600 have been identified as having a disease and 400 have been identified as disease-free.
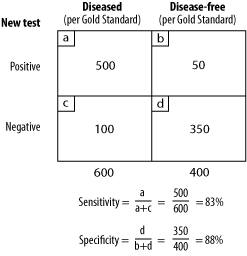
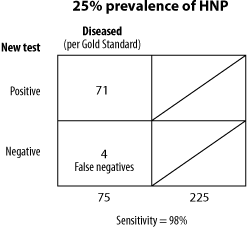
Since both of these calculations are derived from separate columns (i.e., a/a+c and d/b+d) the relative proportions of diseased and disease-free individuals in the study does not affect our calculation. However, the prevalence of a disease in a given population will have a definite impact on the relative numbers of false positives and false negatives. Let's look at two examples of different prevalences (5 percent and 50 percent) and, using our earlier results of 83 percent sensitivity and 88 percent specificity, calculate the number of false negatives and false positives we can expect in the two populations.

Notice that in the lower prevalence population we actually have more false positives than true positives, illustrating an important concept in statistics. Even though sensitivity and specificity calculations are not influenced by the prevalence of a disease in a given population, the number of false positives and false negatives identified are. This may seem confusing or ambiguous at first, but in a moment it will make perfect sense. Let's look at a real example of how this can apply to research.

The predictive value of a test is a measure of the test's ability to either rule in or rule out a disease because it tells us how likely it is that someone with a positive test actually does have a disease (positive predictive value) or how likely it is that someone with a negative test actually does not have a disease (negative predictive value). We can use the same examples as we had in Figs. 2 & 3 just to save space. When we calculated sensitivity and specificity earlier, we were concerned only with the (vertical) columns of our 2 x 2 tables. Now we will calculate across rows (horizontally). Those mathematically inclined will realize that in this calculation the prevalence does become important.
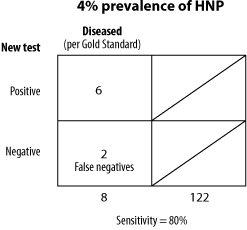
Referring back to Fig. 2, the population with a five percent prevalence, we can calculate these values as follows:
Positive predictive value = a/a+b = 42/(42+64) = 40 percent
Negative predictive value = d/c+d = 836/(8+836) = 99 percent
These results are not surprising since we found that there were more false positive than true positives -- we can't place too much faith in a positive test when there's a 60 percent chance it should have been negative. Now let's look at Fig. 3, the population with a 50 percent prevalence:
Positive predictive value = a/a+b = 415/415+60 = 87 percent
Negative predictive value = d/c+d = 440/85+440 = 83 percent
With an understanding of these measurements you can see how researchers can effectively stack the deck in a given project, an approach which is usually not deliberate but which can sometimes yield results that are misleading. Naturally, when we take a study population of 100 patients, 80 of which have the given disorder we intend to look for with our new test, it is quite likely that we will wind up with fairly impressive figures. However, we must ask ourselves an important question about the true prevalence of the condition in the real population of patients we are likely to see in our offices. If the prevalence is only three percent rather than 80 percent how much confidence can we put it the test? Now you can figure it out yourself if you know the sensitivity and specificity of the test and the approximate prevalence of the disorder.
Click here for previous articles by Arthur Croft, DC, MS, MPH, FACO.